



Next: Referências Bibliográficas
Up: Plano de Trabalho
Previous: Metas
Sumário
Esta seção contém a proposta de um algoritmo que relaciona todos os tópicos que estão sendo estudados e desenvolvidos para a conclusão do projeto de mestrado. O fluxograma dessa proposta pode ser visto na figura 19 tendo sido documentado em [63].
Figura:
Esquema do projeto de reconhecimento a partir de seqüências de vídeo.
|
|
Basicamente, esse projeto foi criado a partir da união das duas idéias para redução da complexidade discutidas na seção 7, ou seja, redução da dimensionalidade através do uso de imagens menores, e também de seleção de características.
Assim, o sistema de reconhecimento utilizará quatro recortes da imagem de entrada: para os dois olhos, o nariz e a boca. As tarefas de detecção e perseguição de pontos característicos da face, bem como a de normalização das imagens de olhos, nariz e boca não fazem parte do escopo deste projeto. Mas é importante ressalvar que essas tarefas serão realizadas através de um método baseado em Gabor Wavelet Networks [10]. Esse método detecta e persegue os pontos característicos e determina os parâmetros da transformação afim que leva uma imagem frontal e a uma determinada escala à posição em que os pontos se encontram. Através desses parâmetros, pode-se realizar a inversa da transformação afim e obter imagens normalizadas. Esse processo de normalização é importante para reduzir as variações dos padrões introduzidas pelos movimentos da face, o que melhora o desempenho do sistema de reconhecimento.
Assim, as imagens utilizadas tanto para treinar quanto para testar o sistema de reconhecimento serão constituídas por imagens das regiões características normalizadas com relação à transformação afim.
Para efetuar o treinamento, será utilizada uma seqüência de vídeo por pessoa. O reconhecimento será feito utilizando análise de componentes principais (PCA), com uma base para cada característica. Alguns detalhes sobre PCA encontram-se na seção 4.2. Assim, será criada uma base para olhos esquerdos, outra para olhos direitos, uma para os narizes e outra para as bocas, obtendo-se as eigenfeatures (eigenlefteyes, eigenrighteyes, eigennoses e eigenmouth). Detalhes sobre os termos recém-citados encontram-se na seção 7.1.
Após a obtenção de todas as eigenfeatures, essas são concatenadas de forma a criar um espaço de características que consiste na soma dos espaços vetoriais formados por todas as eigenfeatures (detalhes sobre soma de espaços vetoriais podem ser encontrados em [47]). Para reduzir a dimensionalidade desse espaço, será aplicado o algoritmo de se seleção de características descrito na seção 7.2.2. A figura 20 esquematiza o método descrito.
Figura:
Geração do espaço de características.
|
|
A utilização de um algoritmo de seleção de características é motivada por poder-se dizer que essa abordagem constitui-se de um tipo de fusão de multisensores, se considerarmos que cada região característica da face é obtida através de um meio de aquisição diferente. Nesse ponto surge a necessidade de reduzir a dimensionalidade de maneira a valorizar os sensores com maior poder de discriminação. Além disso, como pode-se concluir da seção 7.2.1, a aplicação de algoritmos de seleção de características pode proporcionar melhora na taxa de acerto de classificadores.
Além disso, conforme dito anteriormente, a transformada PCA faz uma rotação no espaço de características de forma que o primeiro vetor da base fique na direção em que há mais variação entre os padrões, o segundo vetor na direção em que ocorre a segunda maior variação perpendicular ao primeiro, e assim por diante. Ou seja, a variação específica entre elementos de classe diferente não é otimizada.
Em [13], os autores mostram os resultados de uma abordagem de reconhecimento parecida com a abordagem proposta aqui. Trata-se da aplicação de seleção de características usando a técnica de busca flutuante (métodos SFS) sobre as características obtidas a partir da transformada PCA sobre imagens de dígitos.
Outro fator motivador para a aplicação de seleção de características sobre PCA está em um dos resultados obtidos em [19], em que o desempenho de um sistema de reconhecimento de pessoas baseado em PCA foi melhorado com a eliminação dos três primeiros auto-vetores. Os autores de [19] justificam que há algumas evidências de que esses auto-vetores são influenciados pelas mudanças de iluminação, e não por variações inter-classes. Provavelmente, esse fato se deve principalmente ao fato de que em [19] foram realizados testes com imagens apresentando grandes variações de iluminação, e os primeiros auto-vetores apontam para o sentido em que há maior variação dos dados. Esse resultado provem evidencias de que é possível obter resultados melhores aplicando um método de seleção de características sobre as eigenfeatures ao invés de utilizar simplesmente os primeiros auto-vetores.
Em [31] os autores declararam que não estava definida uma estratégia de realizar fusão ótima das informações obtidas das diferentes regiões da face. Tanto em [31], como em [23], foi utilizado um classificador para cada região da face e os resultados foram combinados utilizando um super-classificador. No caso de [23], a classificação das regiões foi feita usando template matching e a combinação foi realizada através da soma dos resultados (graus de similaridade dos templates de cada pessoa). Já em [31], a classificação das regiões foi feita por vizinho mais próximo no eigenspace e a combinação, através do esquema de votação. A estrutura proposta aqui (seleção de eigenfeatures) é uma forma de fundir os dados para a utilização de um único classificador para todas as regiões das imagens. Um super-classificador será utilizado somente para combinar os resultados de classificação de cada quadro da seqüência de vídeo.
Para efetuar o reconhecimento de pessoas em seqüências de vídeo, primeiro os quadros deverão ser representados no espaço de características criado a partir de eigenfeature selection. Inicialmente o espaço de características deverá ser povoado pelos elementos de treinamento obtidos a partir de seqüências de vídeo em que as pessoas variem a pose e a expressão facial. Dessa forma, cada classe poderá ter muitos elementos de treinamento. Posteriormente, para cada pessoa, uma outra seqüência de vídeo será utilizada para testar o sistema. Cada quadro das seqüências de teste será classificado individualmente através de um classificador de mínima distância ao protótipo ou o k-vizinhos mais próximos (descritos na seção 6). Conforme mensionado anteriormente, um super-classificador (ou método de combinação) será utilizado para decidir o resultado da classificação a partir dos resultados obtidos pelos quadros individuais da seqüência. Pretende-se utilizar o esquema de votação para efetuar essa tarefa, mas poderão ser utilizados outros. Alguns super classificadores foram descritos e avaliados em [13].
Esse trabalho incluirá avaliação de desempenho do classificador através de uma estratégia parecida com a ``deixe um fora'' (leaving-one-out) [14]. Dado que se dispões de 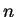 amostras por classe, a estratégia leaving-one-out consiste de treinar o classificador com
amostras por classe, a estratégia leaving-one-out consiste de treinar o classificador com 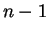 padrões por classe e testá-lo com uma amostra, e alternar o elemento de teste, de forma que todos os elementos sejam testados a partir do treinamento dos restantes. Nossa proposta é de dispor de algumas seqüências de vídeo para cada pessoa e realizar testes alternando seqüências para testar e para treinar o classificador.
Através dessa avaliação poderá ser determinado qual dos classificadores de quadros será utilizado (K-vizinhos ou distância ao protótipo), bem como o valor K, caso o classificador de k-vizinhos mais próximo seja escolhido. Também poderão ser testadas várias estratégias de super classificação.
Uma outra aplicação possível para esse trabalho se refere ao reconhecimento de expressões faciais. Para isso basta realizar o mesmo processo, com a diferença de que as classes consideradas nas imagens de treinamento serão classes de expressões faciais, e não identificação de pessoas.
padrões por classe e testá-lo com uma amostra, e alternar o elemento de teste, de forma que todos os elementos sejam testados a partir do treinamento dos restantes. Nossa proposta é de dispor de algumas seqüências de vídeo para cada pessoa e realizar testes alternando seqüências para testar e para treinar o classificador.
Através dessa avaliação poderá ser determinado qual dos classificadores de quadros será utilizado (K-vizinhos ou distância ao protótipo), bem como o valor K, caso o classificador de k-vizinhos mais próximo seja escolhido. Também poderão ser testadas várias estratégias de super classificação.
Uma outra aplicação possível para esse trabalho se refere ao reconhecimento de expressões faciais. Para isso basta realizar o mesmo processo, com a diferença de que as classes consideradas nas imagens de treinamento serão classes de expressões faciais, e não identificação de pessoas.
Next: Referências Bibliográficas
Up: Plano de Trabalho
Previous: Metas
Sumário
Teofilo Emidio de Campos
2000-09-18
![\includegraphics[width=9.6cm, height=12cm]{atibaia_esquema.ps}](img110.png)
![\includegraphics[width=6cm, height=12cm]{atibaia_feat_space.eps}](img111.png)