As medidas de distância entre agrupamentos ou classes mais utilizadas como função critério para seleção de característica são mais adequadas a conjuntos convexos, tendendo a privilegiar conjuntos linearmente separáveis (por exemplo, a distância de Mahalanobis). O problema é que com esses critérios de distância não é possível detectar bons agrupamentos côncavos ou com médias próximas, como do da figura 9, em que a distribuição dos padrões de uma classe encontra-se no interior da distribuição dos padrões de outra classe, mas as distribuições das classes não se interceptam. Nesse caso, dificilmente um critério de distância tradicional identificaria o potencial desses agrupamentos, apesar do fato dos dois agrupamentos estarem bem definidos, possibilitando a obtenção de boas taxas de reconhecimento com um classificador de k-vizinhos mais próximos.
Visando evitar esse problema, foram realizados testes com seleção de características utilizando uma função critério que, juntamente com o algoritmo de seleção, maximiza a distância entre padrões que pertencem a classes diferentes e minimiza a distância entre elementos que pertencem à mesma classe. Isso é feito independentemente da forma da distribuição dos padrões no espaço de características.
Um critério de distância que possui essas propriedades é a distância fuzzy baseada em tolerância, proposta em [60]. Nesse critério, a distância é determinada através de uma vizinhança em torno de cada padrão de treinamento.
Para utilizar esse critério de distância deve-se, inicialmente, transformar os conjuntos de treinamento em conjuntos nebulosos (fuzzy). Foram realizados testes com essa função critério e publicados em [57], numa colaboração com a pesquisadora francesa Isabelle Block. A função de fuzzyficação utilizada foi a seguinte:
(9)
em que é um padrão, é a função de pertinência desse padrão ao conjunto , representa o suporte da classe e é a distância Euclidiana. O suporte pode ser definido, por exemplo, como o baricentro do conjunto , de forma que a função de pertinência é inversamente proporcional à distância do padrão ao suporte de cada classe.
Para definir a distância fuzzy baseada em tolerância, inicialmente é definida uma distância local:
(10)
em que denota uma bola (espacial) fechada, de raio centrada em . Assim, pode-se definir a distância fuzzy baseada em tolerância por [60]:
(11)
onde representa todo o espaço de características.
Para avaliar o desempenho desse critério de distância com o intuito de efetuar seleção de características, foram feitos testes com os métodos de busca SFS [54] em dados artificiais. O critério de distância fuzzy baseado em tolerância foi comparado com o desempenho de um classificador de distância ao protótipo. Para avaliar o desempenho dos conjuntos de dados foram utilizados dois classificadores: k-vizinhos mais próximos e o de mínima distância ao protótipo.
Esse algoritmo foi testado com um conjunto de dados artificiais de seis dimensões, duas classes, com 100 exemplos por classe. As figuras 16, 17 e 18 mostram a distribuição para cada par de dimensões. Esse conjunto de dados foi criado para permitir que seja feita seleção de características reduzindo a dimensionalidade para 2, o que permite visualização dos dados.
Figura:
Dados artificiais utilizados em [57]. (*) = classe A, (o) = classe B. Nas características 1 e 2, os padrões possuem distribuições Gaussianas com médias diferentes.
Figura:
Continuação da figura 16. Distribuições ruidosas nas características 3 e 4.
Figura:
Continuação da figura 17. Nas características 5 e 6, a classe B possui distribuição Gaussiana ``dentro'' da classe A, a qual é gerada como uma mistura de 4 Gaussianas formando um anel.
Antes de realizar a seleção de características, os dados foram normalizados de forma a ficarem com média 0 e variância unitária. Isso é importante para evitar problemas com os classificadores, pois esses são baseados em distância Euclidiana [19].
Para avaliar os resultados, os dados com as distribuições descritas nas figuras 16, 17 e 18, com 100 amostras para cada classe, foram gerados 100 vezes. A distância foi utilizada com e o classificador de k-vizinhos com .
Conforme esperado, o seletor de características baseado em distância nebulosa selecionou as características 5 e 6 em todos os 100 testes. Já o algoritmo de seleção com o desempenho do classificador frequentemente selecionou as caracterís 1 e 2, mas várias outras combinações de características também foram selecionadas.
Quanto ao desempenho obtido com o classificador de k-vizinhos mais próximos, os resultados estão na tabela 3. Quando o classificador k-vizinhos foi testado som interseção entre o conjunto de treinamento e o de testes, foram utilizados 67 padrões para treinar o classificador e 33 para testá-lo.
Tabela:
Desempenho médio (após 100 testes) do classificador k-vizinhos para os subconjuntos de características selecionados.
Classificador
Conjunto de treinamento
Sem interseção entre
-----
igual ao
o conjunto de
Critério
conjunto de testes
treinamento e o de testes
Classificador
95,5611%
89,4706%
Distância nebulosa
99,9950%
95,0735%
Os resultados obtidos mostram que a distância nebulosa baseada em tolerância permite a obtenção de bons resultados para conjuntos côncavos ou com conjuntos apresentando sobreposição entre classes diferentes. Maiores detalhes sobre esse trabalho podem ser obtidos em [57].
Next:Plano de Trabalho Up:Testes com Seleção de Previous:Teste de algoritmosSumário
Teofilo Emidio de Campos
2000-09-18
![\begin{displaymath}
d_p^{\tau} (\mu_A, \mu_B) = [ \int_{{\cal S}}
[d_x^{\tau}(\mu_A,\nu_B)]^p dx ]
^{1/p},
\end{displaymath}](img103.png)
![\includegraphics[width=8cm, height=8cm]{icapr_a.eps}](img105.png)
![\includegraphics[width=8cm, height=8cm]{icapr_c.eps}](img107.png)
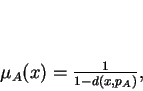
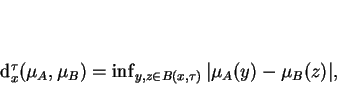
![\includegraphics[width=8cm, height=8cm]{icapr_b.eps}](img106.png)